Nachrichten Tweets
Franziska Löw
11 June, 2018
rm(list = ls())
## --- Load Packages --- ##
library(rtweet)
library(dplyr)
library(ggplot2)
library(rvest)
library(tidyr)
library(wordcloud2)
library(igraph)
library(ggraph)
library(stringr)
library(tm)
library(tidytext)
library(stringi)
## ---- My Functions --- ##
source("functions.R")
## --- Set Stylings --- ###
knitr::opts_chunk$set(message=FALSE, warning=FALSE)
theme_set(
theme_bw(base_size = 14) +
theme(
plot.title = element_text(face = "bold", size = 14,
margin = margin(0, 0, 4, 0, "pt")),
plot.subtitle = element_text(size = 12),
plot.caption = element_text(size = 6, hjust = 0),
axis.title = element_text(size = 10),
panel.border = element_blank()
)
)
## --- Global Variables --- ##
# Define Color
Mycol <- RColorBrewer::brewer.pal(8, "Dark2")
# Define http pattern
http <- paste(c("http.*","https.*"), sep = "|")
# Define Stopwords
stopwords <- data_frame(
word = stopwords("german")
) %>% rbind(
data_frame(word = c("t.co","via","mal","dass","mehr", "amp",
"beim", "ab","sollen","ganz","sagt",
"schon","rt","gibt", "ja", "natürlich"))
)Welche Nachrichten-Inhalte werden aktuell bei Twitter diskutiert? Um das herauszufinden, haben wir die aktuellsten deutschsprachigen Tweets gesammelt, die einen Link zu einer Nachrichtenseite beinhalten. Die Tweets wurden mit Hilfe des R Packetes rtweet über die REST API ausgelesen. Der gesamte Code ist hier einzusehen.
Folgende Variablen sind in unserem Datensatz vorhanden.
load("../data/2018-06-11.Rda")
colnames(rt)## [1] "status_id" "created_at"
## [3] "user_id" "screen_name"
## [5] "text" "source"
## [7] "reply_to_status_id" "reply_to_user_id"
## [9] "reply_to_screen_name" "is_quote"
## [11] "is_retweet" "favorite_count"
## [13] "retweet_count" "hashtags"
## [15] "symbols" "urls_url"
## [17] "urls_t.co" "urls_expanded_url"
## [19] "media_url" "media_t.co"
## [21] "media_expanded_url" "media_type"
## [23] "ext_media_url" "ext_media_t.co"
## [25] "ext_media_expanded_url" "ext_media_type"
## [27] "mentions_user_id" "mentions_screen_name"
## [29] "lang" "quoted_status_id"
## [31] "quoted_text" "retweet_status_id"
## [33] "retweet_text" "place_url"
## [35] "place_name" "place_full_name"
## [37] "place_type" "country"
## [39] "country_code" "geo_coords"
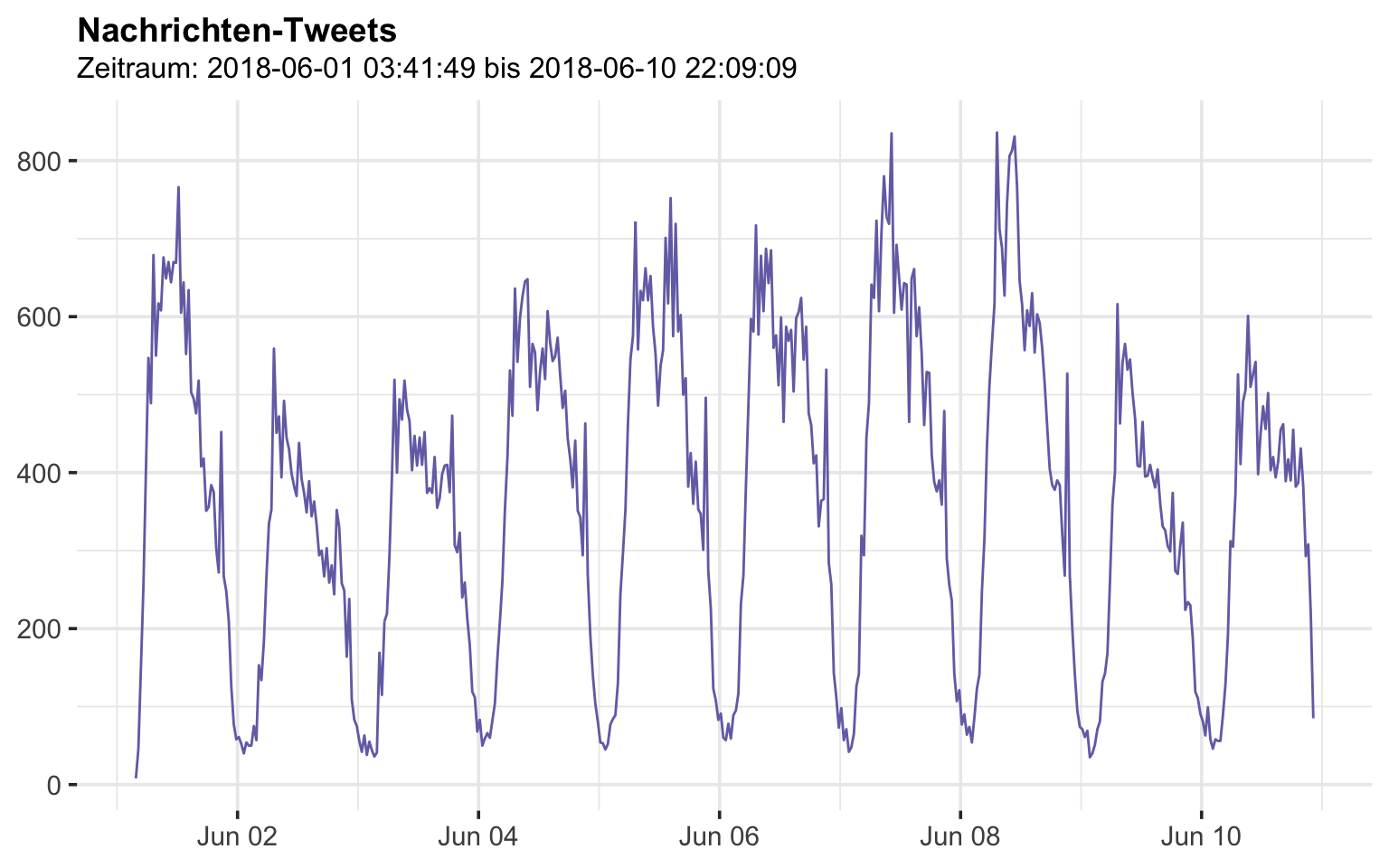
## [41] "coords_coords" "bbox_coords"Zeitraum
rt %>%
ts_plot("30 minutes",
color = Mycol[3]) +
theme(plot.title = element_text(face = "bold")) +
labs(
x = NULL, y = NULL,
title = "Nachrichten-Tweets",
subtitle = paste("Zeitraum:",min(rt$created_at),"bis",max(rt$created_at))
) 
Retweets
Welche Tweets wurden am häufigsten geteilt? Die top 10 sind:
rt %>%
filter(is_retweet == FALSE ) %>%
dplyr::select(screen_name, text, retweet_count) %>%
group_by(screen_name, text) %>%
summarise(retweet_count = sum(retweet_count)) %>%
arrange(desc(retweet_count)) %>%
.[1:10,] %>%
#knitr::kable(align = "l")
htmlTable::htmlTable(align="l")| screen_name | text | retweet_count | |
|---|---|---|---|
| 1 | TheRickWilson |
Die in jail. https://t.co/H9jWePItYT |
1270 |
| 2 | DPolGHH | #DPolGHH »Und ja, natürlich gibt es auch deutsche Kriminelle. (…) Das stimmt, und jedes Verbrechen ist eines zu viel. Und genau deswegen brauchen wir ganz sicher nicht auch noch Verbrecher, die kein Recht haben, in Deutschland zu sein.« #Susanna https://t.co/4OSzTxFbB0 | 913 |
| 3 | ESukhni | Der Befund ist verheerend: #Rechtspopulisten bestimmen in hohem Maße die Themen von TV-Talkshows. Das ARD-Magazin„Monitor“ hat alle 141 Sendungen im ersten und zweiten Programm des vergangenen Jahres ausgewertet – von„Anne Will“ bis „Maybrit Illner“. https://t.co/dGxsU5sbgA | 898 |
| 4 | the_langow | Es gibt Menschen, die reden über Vogelschiss und wollen ungeschehen machen, was passiert ist, und andere, die hauen jeden Tag 10 Stunden lang Buchstaben und Namen in Stolpersteine. Reden wir lieber über letztere: https://t.co/ZXTAxICR2e | 615 |
| 5 | mspro | wow! das berühmte marshmellow-experiment (nimm jetzt einen oder später zwei) wurde jahrzehntelang irreführend interpretiert. forscher haben jetzt einfach mal nach klassenzugehörigkeit kontrolliert, et voila! https://t.co/5ryY18TlIY | 580 |
| 6 | Steinhoefel | Diesmal hat sich der sog. “Skandal-Rapper” #FaridBang mit den Falschen angelegt und auf unsere Abmahnung hin klein beigegeben. Ein Kritiker nannte seine Texte einmal “bestürzend dumm”. Dass dies zutrifft, hat er hier erneut unter Beweis gestellt. https://t.co/Ja10zPrLIX | 580 |
| 7 | lawyerberlin |
Frau #Merkel: Packen Sie schon mal die Koffer. Für wohin auch immer (Paraguay, Moabit). Der #Asylbetrug wurde offenbar geduldet und das Volk Verbrechern und Terroristen überlassen. #Bamf-Zentrale wusste seit Jahren Bescheid. Hinweise aus Bremen missachtet https://t.co/HWFvleGmPs |
552 |
| 8 | maxotte_says | #Merkel weist im #Bundestag jede Verantwortung für #Asyl-Affäre von sich. Sie will #Russland dauerhaft von #G8 ausschließen. Wenn jemand in dieses Amt gehievt worden wäre, um der #Bundesrepublik maximalen Schaden zuzufügen, müsste er so handeln wie Merkel. https://t.co/q8ezqC1tJB | 536 |
| 9 | JoanaCotar | Fakt ist, ALLE Altparteien haben den unkontrollierten Zuzug von über einer Mio Menschen bejubelt, jede Kritik, jede Warnung war populistisch. Und jetzt will es keiner gewesen sein. Währenddessen sind die Grenzen immer noch offen und das Chaos geht weiter…https://t.co/0c94Tp4Rti | 531 |
| 10 | henningtillmann |
„Wer sich nicht an unsere Gesetze hält, hat in diesem Land nichts zu suchen.“ 54 Strafzettel in sechs Monaten: https://t.co/dXCfOLYBwD |
489 |
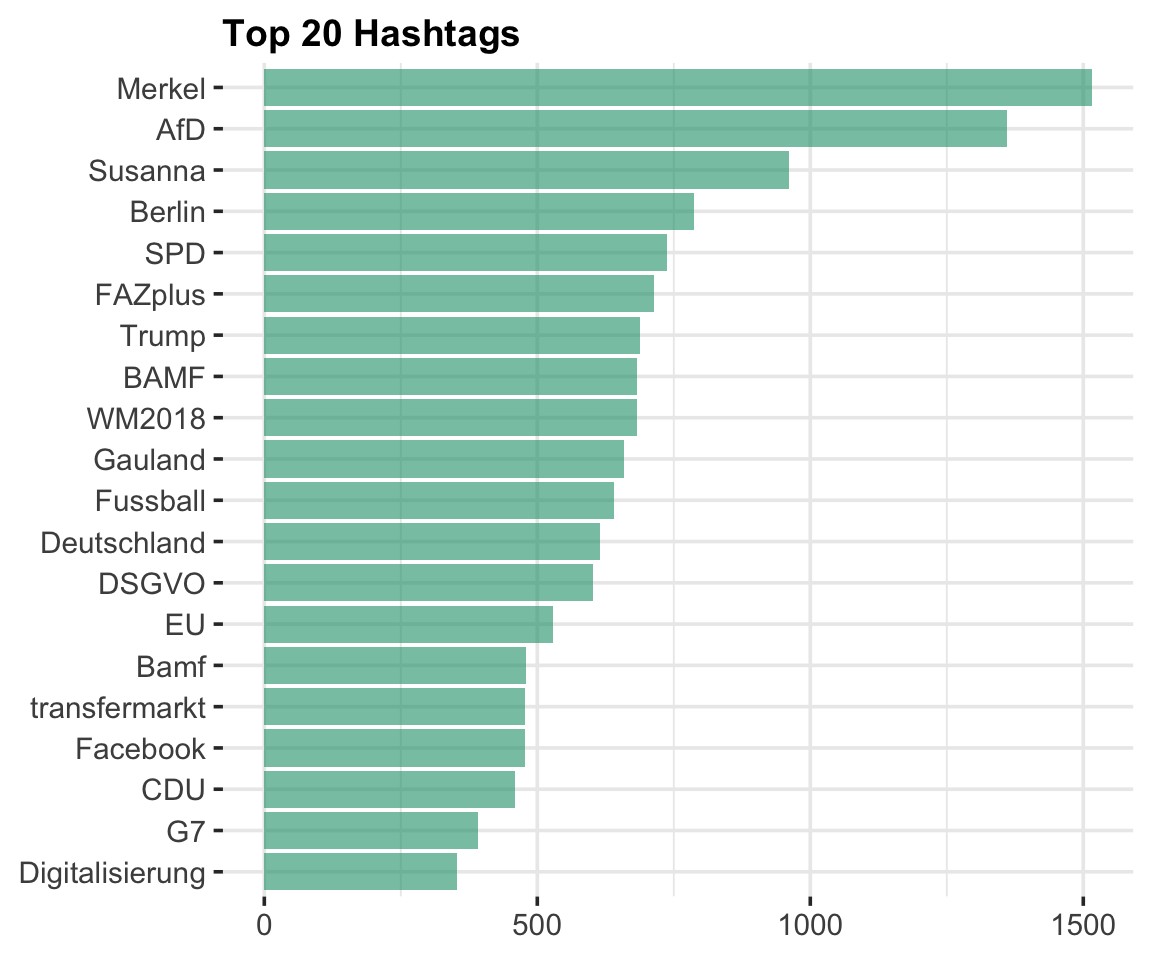
rt$hashtags %>%
unlist() %>%
na.omit() %>%
table() %>%
sort(decreasing = TRUE) %>%
tibble::as_tibble() -> hash_table
colnames(hash_table) <- c("hashtag", "count")
hash_table %>%
top_n(20, count) %>%
ggplot( aes(reorder(hashtag,count), count)) +
geom_col(fill = Mycol[1], alpha = 0.6) +
coord_flip() +
labs(
x = NULL,
y = NULL,
title = "Top 20 Hashtags"
) 
rt_clean <- rt %>%
# First, remove http elements manually
mutate(stripped_text = gsub(http,"", text))
rt_tidy_words <- rt_clean %>%
# Second, remove punctuation, convert to lowercase, add id for each tweet!
dplyr::select(stripped_text) %>%
unnest_tokens(word, stripped_text) %>%
# Third, remove stop words from your list of words
anti_join(stopwords) %>%
# Count Word occurences
count(word, sort = TRUE)
# Finally, plot the top 15 words
rt_tidy_words %>%
top_n(20) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(x = word, y = n, fill = word)) +
geom_col(fill = Mycol[2],
alpha = 0.6) +
xlab(NULL) +
coord_flip() +
labs(y = "Count",
x = "Unique words",
title = "Top 20 Wörter") +
theme(legend.position = "") 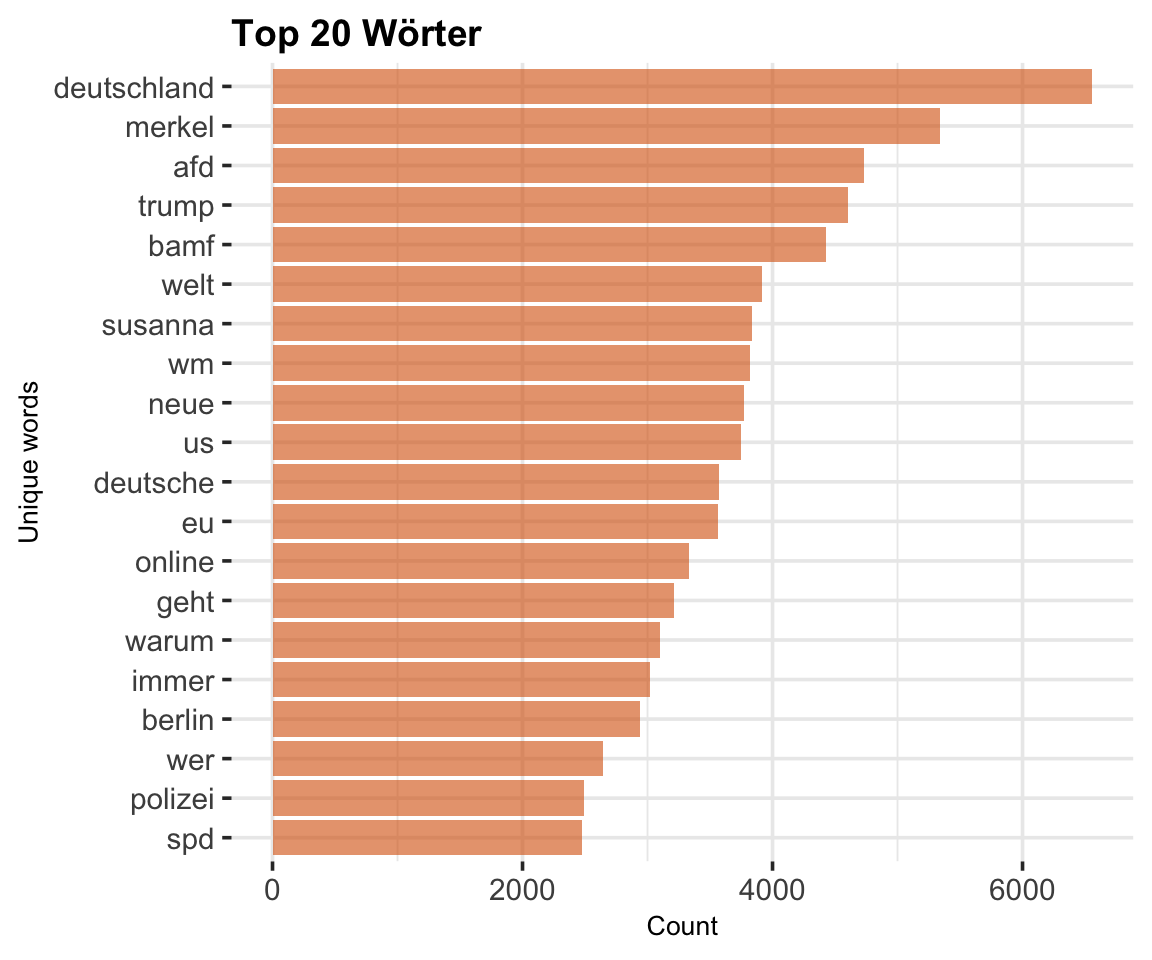
Wordcloud (ges. Wörter)
wordcloud2(rt_tidy_words, size = 1, color = "random-light", backgroundColor = "grey")Nachrichten Medien
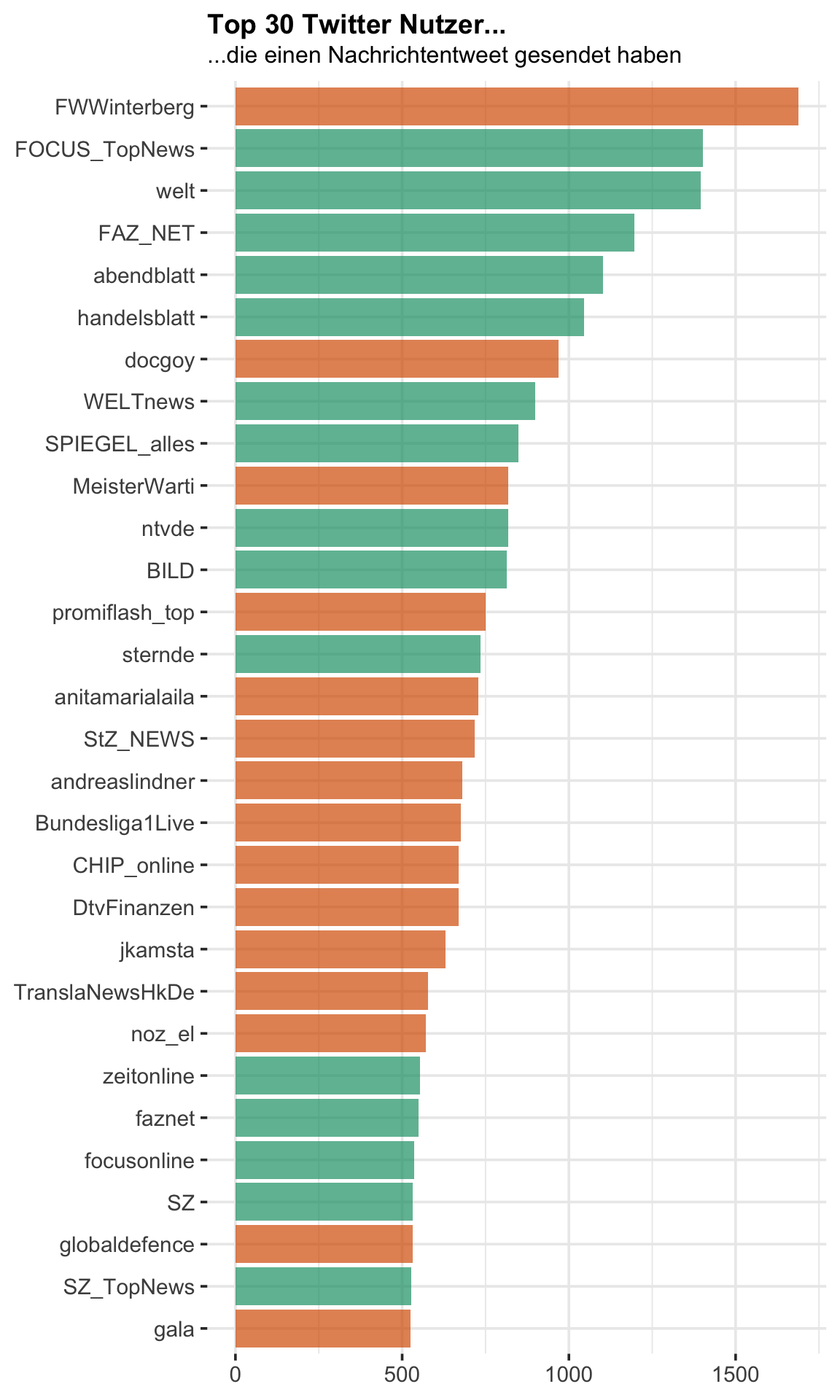
Wir betrachten im nachfolgenden die Tweets, die zu einem der größeren deutschen online Nachrichten gehören. Die jeweiligen Nachrichten-Profile sind in der folgenden Abbildung farblich hervorgehoben:
news <- c("welt", "handelsblatt", "FOCUS_TopNews", "sternde", "faznet",
"focusonline", "SZ", "SZ_TopNews",
"WELTnews", "ntvde", "abendblatt", "FAZ_NET", "Tagesspiegel",
"SPIEGEL_alles", "wiwo", "zeitonline", "BILD")
news_reg <- paste("welt", "handelsblatt", "FOCUS_TopNews", "sternde",
"faznet", "focusonline", "SZ", "SZ_TopNews",
"WELTnews", "ntvde", "abendblatt", "FAZ_NET", "Tagesspiegel",
"SPIEGEL_alles", "wiwo", "zeitonline", "BILD", sep = "|")
name_table <- rt %>%
group_by(screen_name) %>%
tally(sort = TRUE) %>%
ungroup() %>%
mutate(news = ifelse(screen_name %in% news, T, F))
ggplot(name_table[1:30,],
aes(reorder(screen_name,n),n,
fill = factor(news))) +
geom_col(alpha = 0.7,
show.legend = F) +
scale_fill_manual(values = Mycol[c(2,1)]) +
coord_flip() +
labs(
x = NULL,
y = NULL,
title = "Top 30 Twitter Nutzer...",
subtitle = "...die einen Nachrichtentweet gesendet haben"
) 
Für die folgende Analyse wird ein Tweet einem Medium zugewiesen, wenn dieser Tweet (1) entweder direkt von dem Medium gesendet wurde, oder (2) einen Link (“Mention”) zu dem Medium enhält.
rt_news <- rt %>%
mutate(stripped_text = gsub(http,"", text)) %>%
# create variable indicating wich news profile is mentioned
mutate(mentions = stri_join_list(stri_extract_all_words(mentions_screen_name),
sep=", ")) %>%
# filter tweets, that mention these profiles
filter(screen_name %in% news | str_detect(mentions, news_reg)) %>%
# create new variable to assign news website to the tweet
mutate(newsName = ifelse(screen_name %in% news, screen_name, mentions)) %>%
mutate(newsName = str_match(newsName, news_reg))
rt_news %>%
group_by(newsName) %>%
tally() %>%
ggplot(aes(reorder(newsName, n),n)) +
geom_col(fill = Mycol[1], alpha = 0.8) +
coord_flip() +
labs(x="", title="Nachrichten Tweets",
subtitle = "Direkttweet des Mediums oder Nennung in einem Fremdtweet")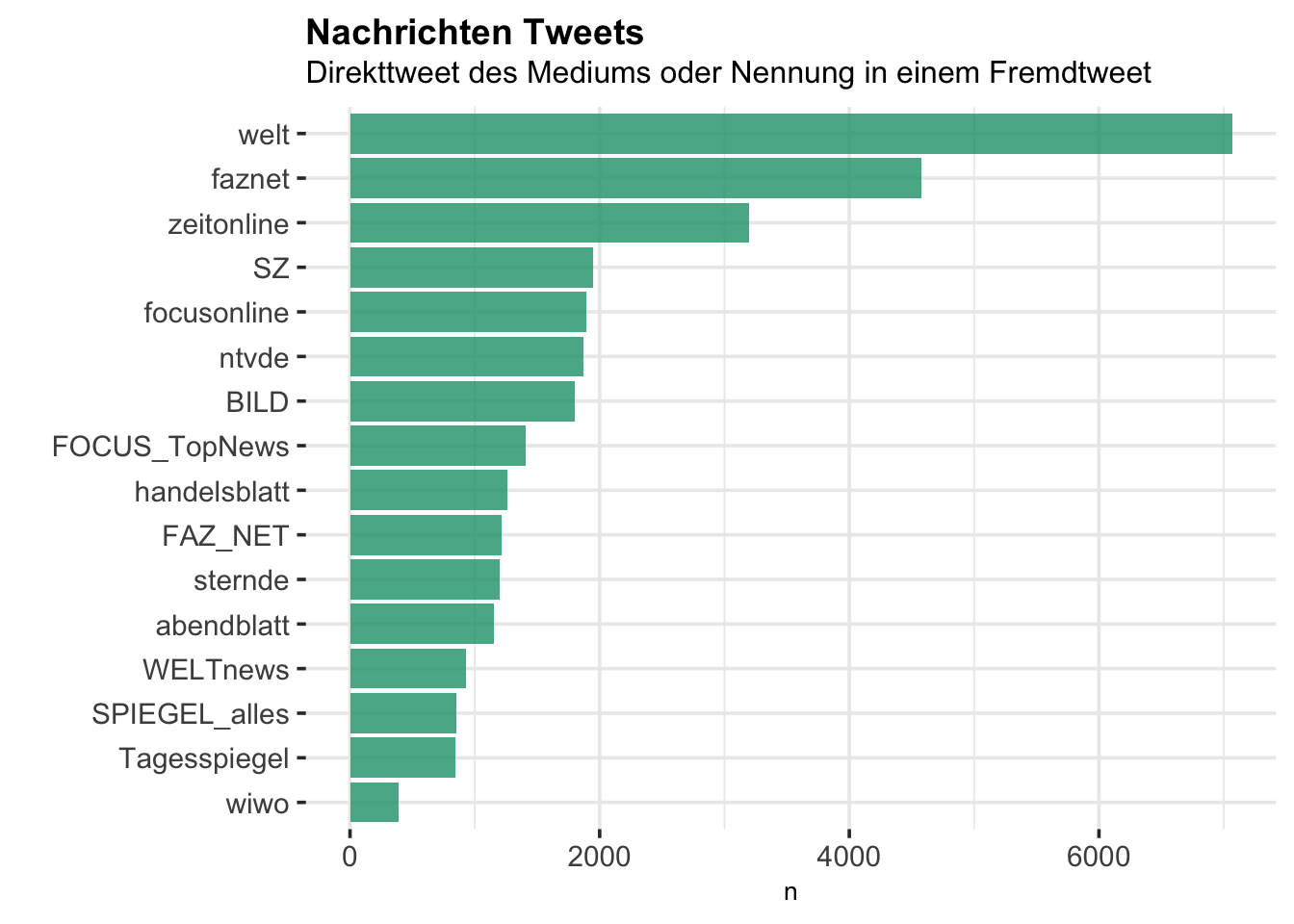
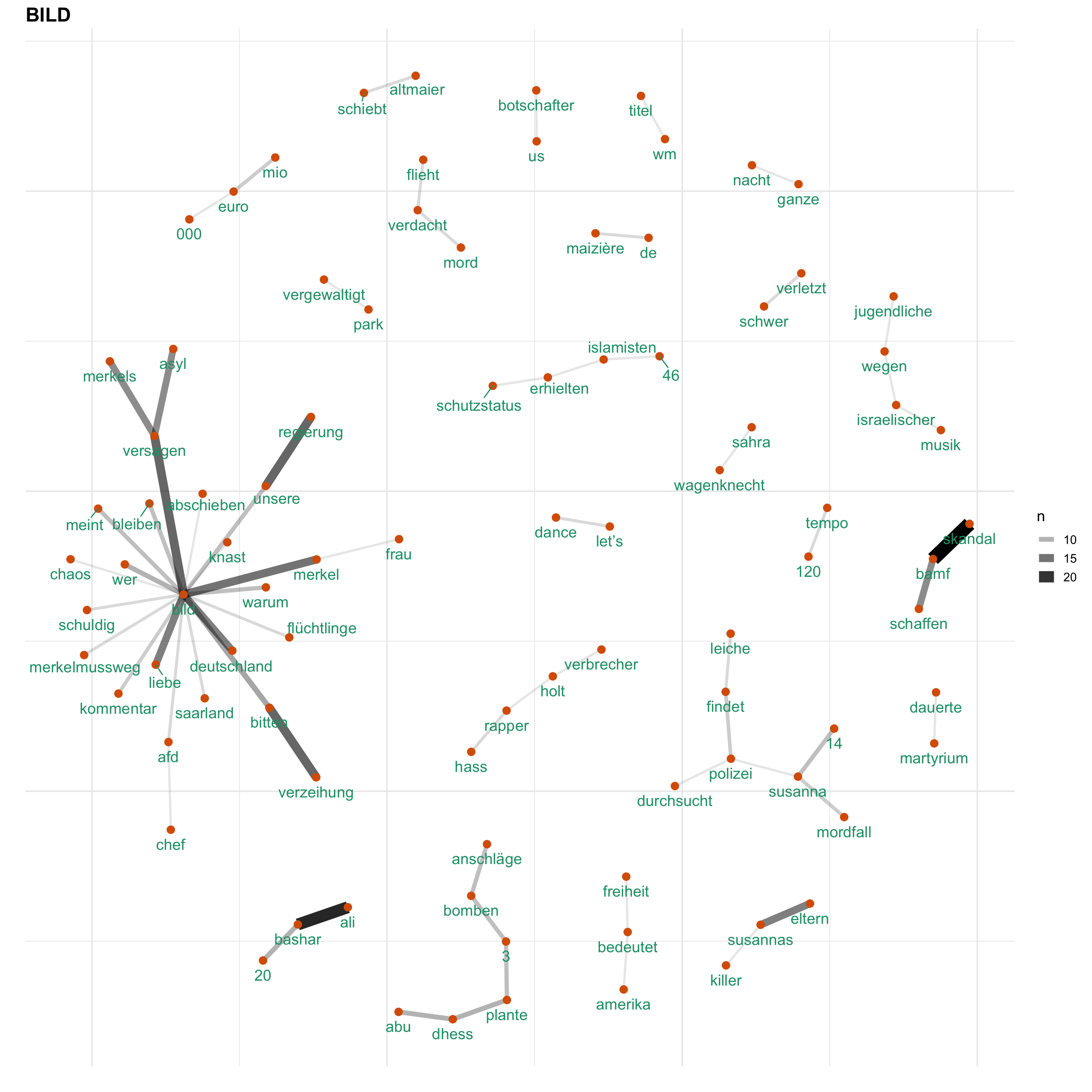
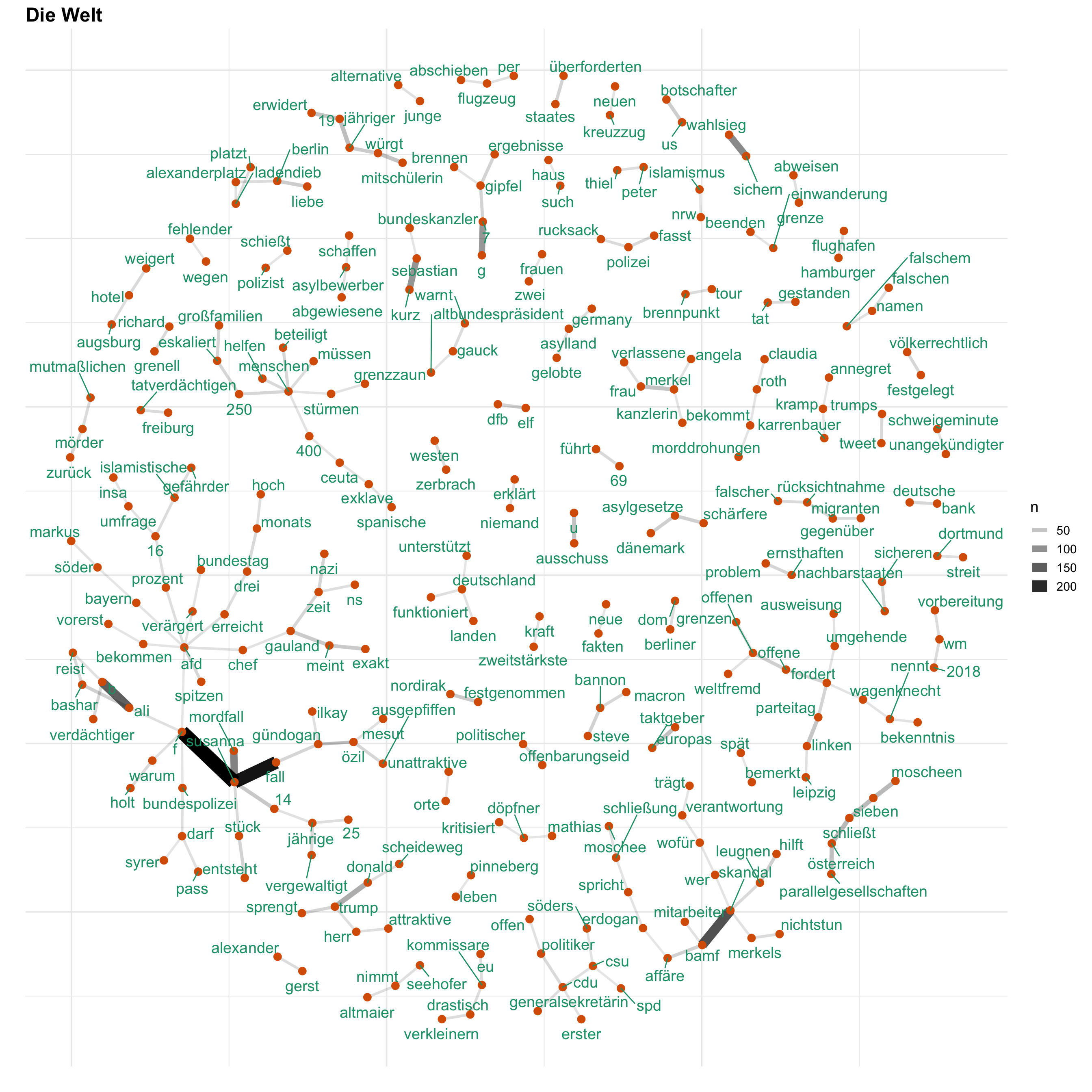
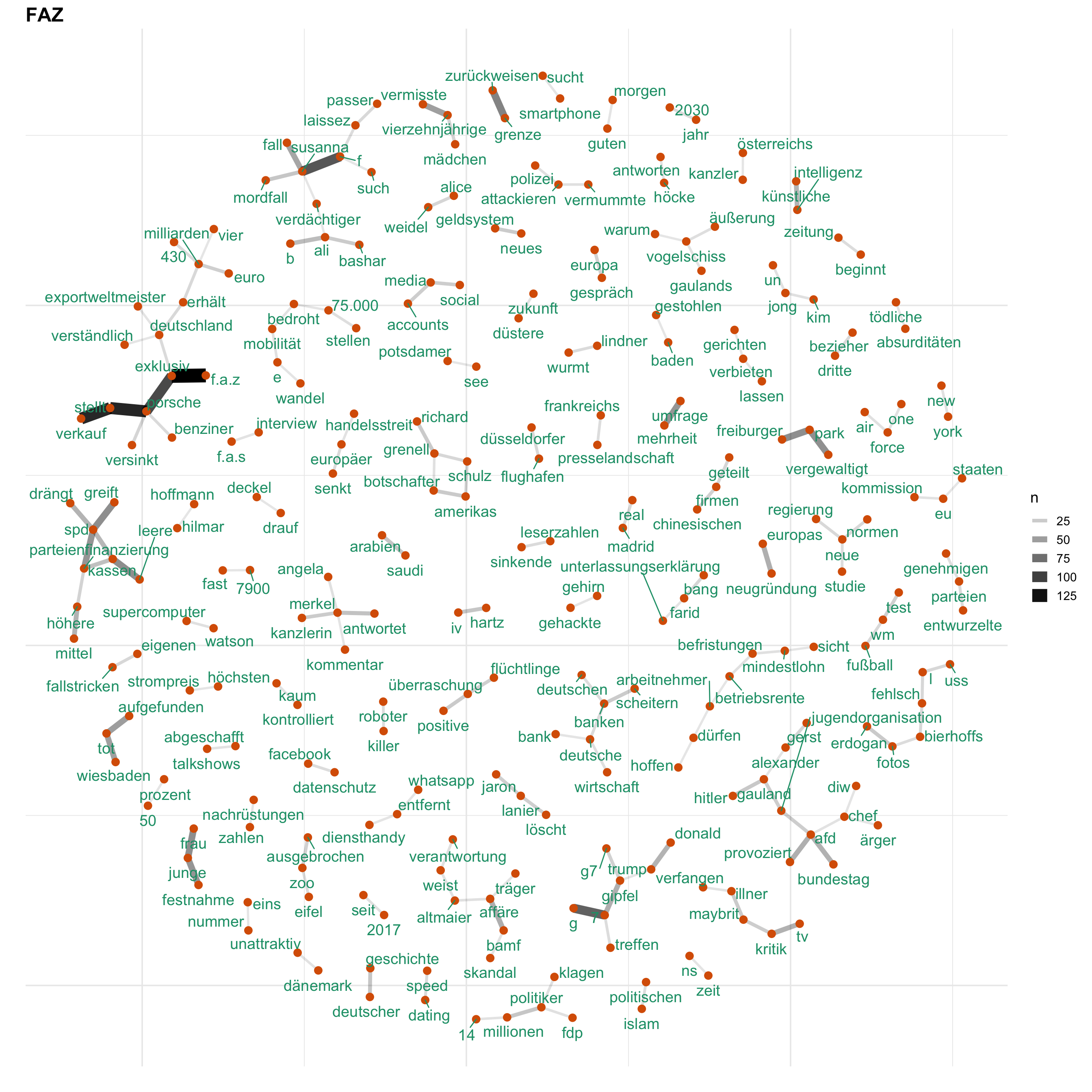
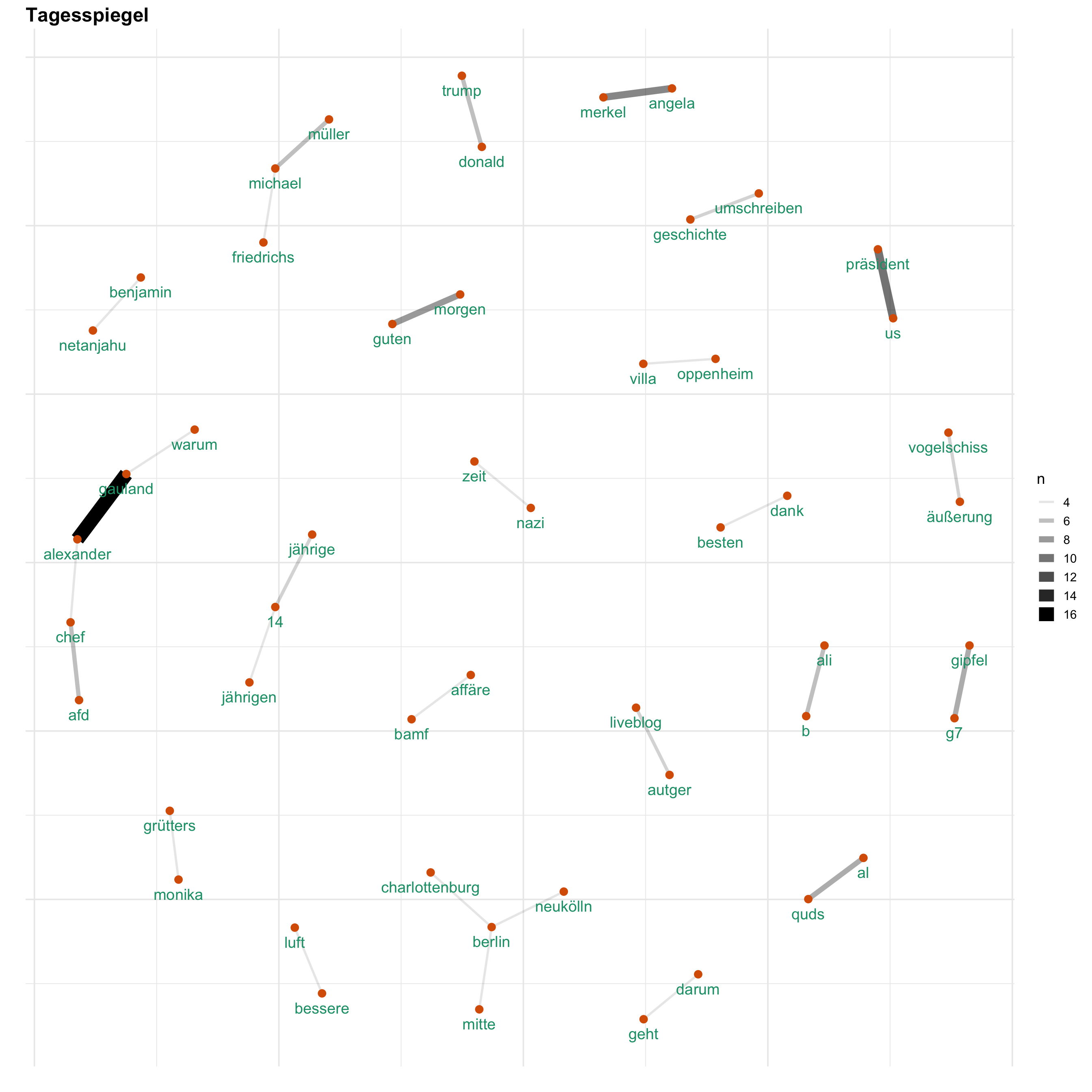
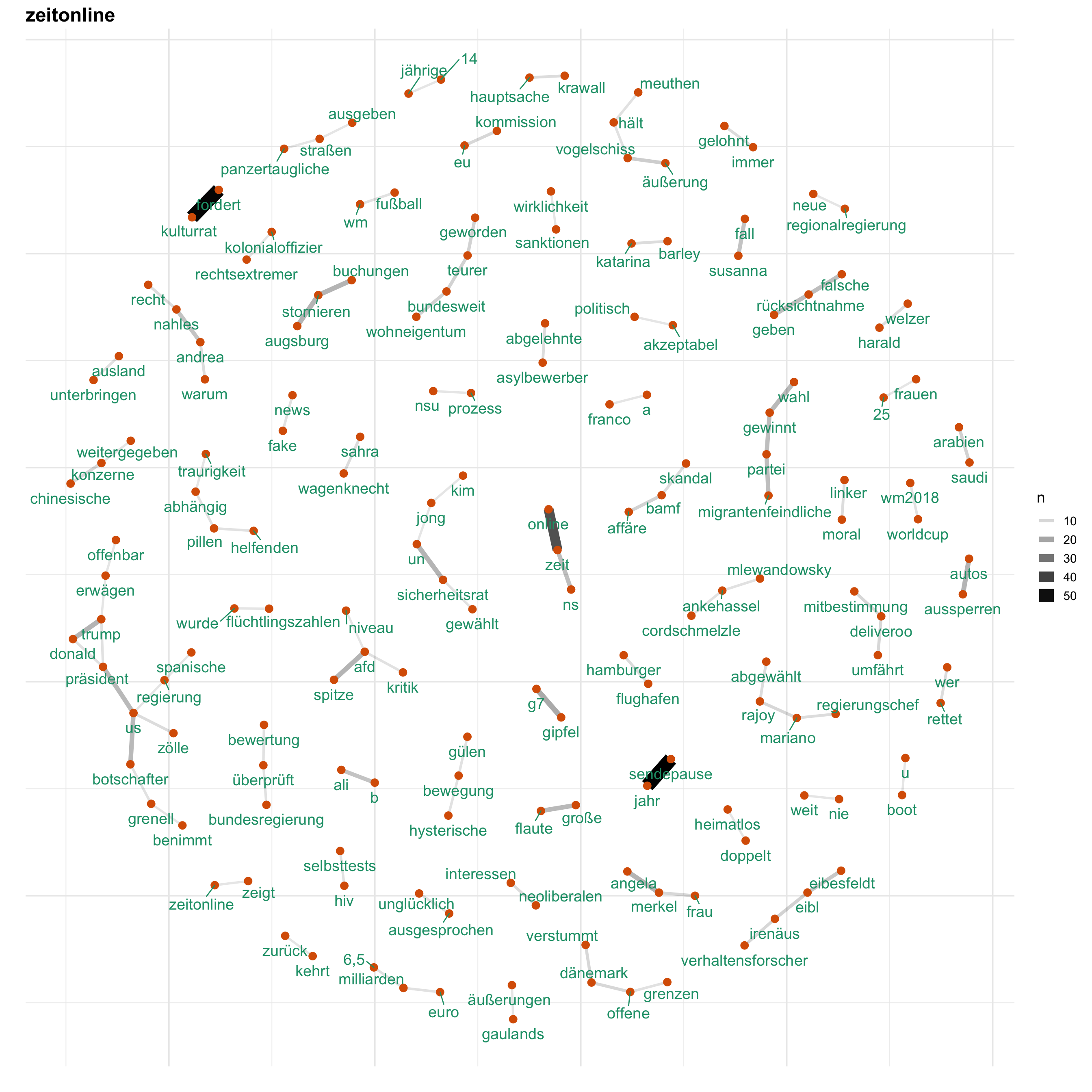
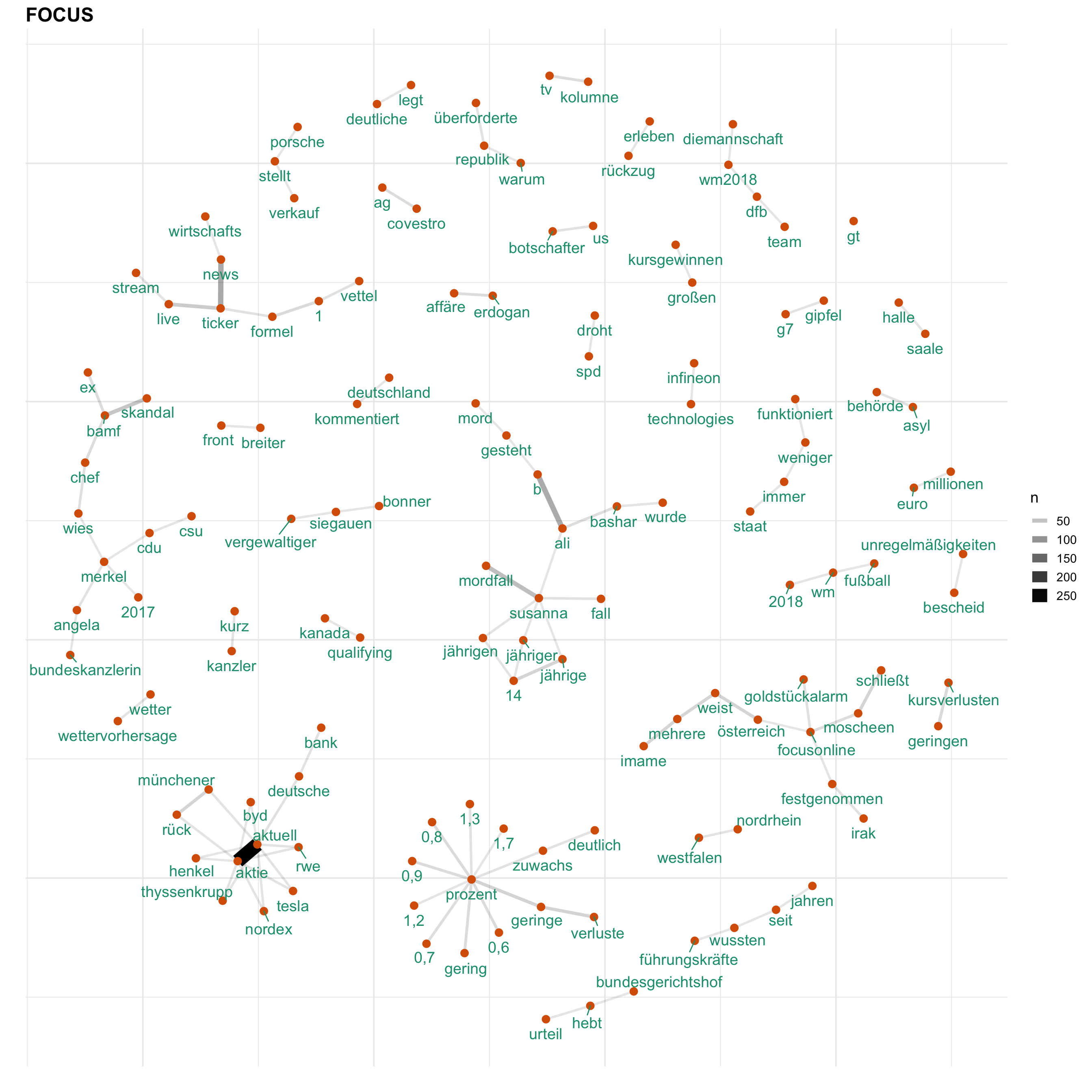
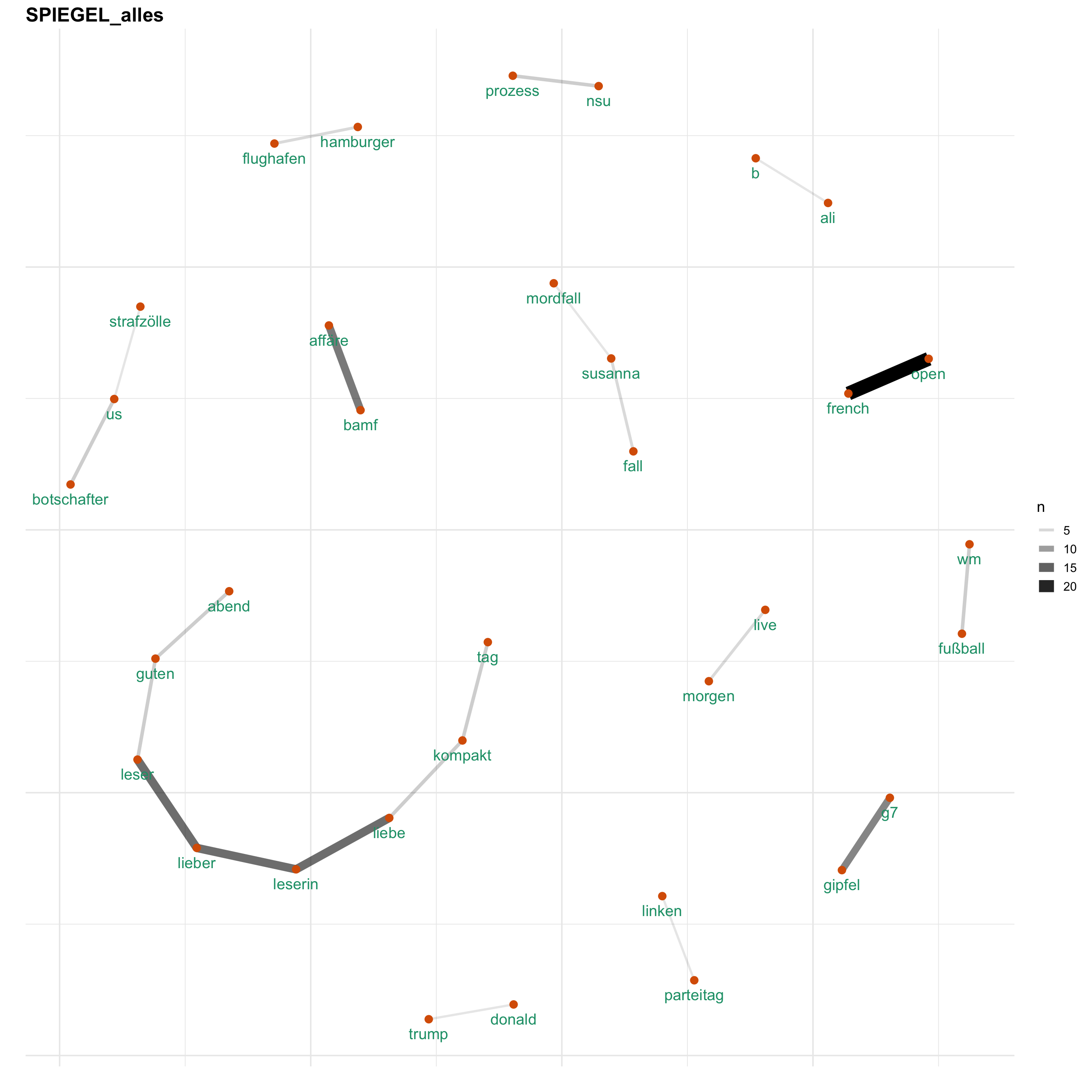
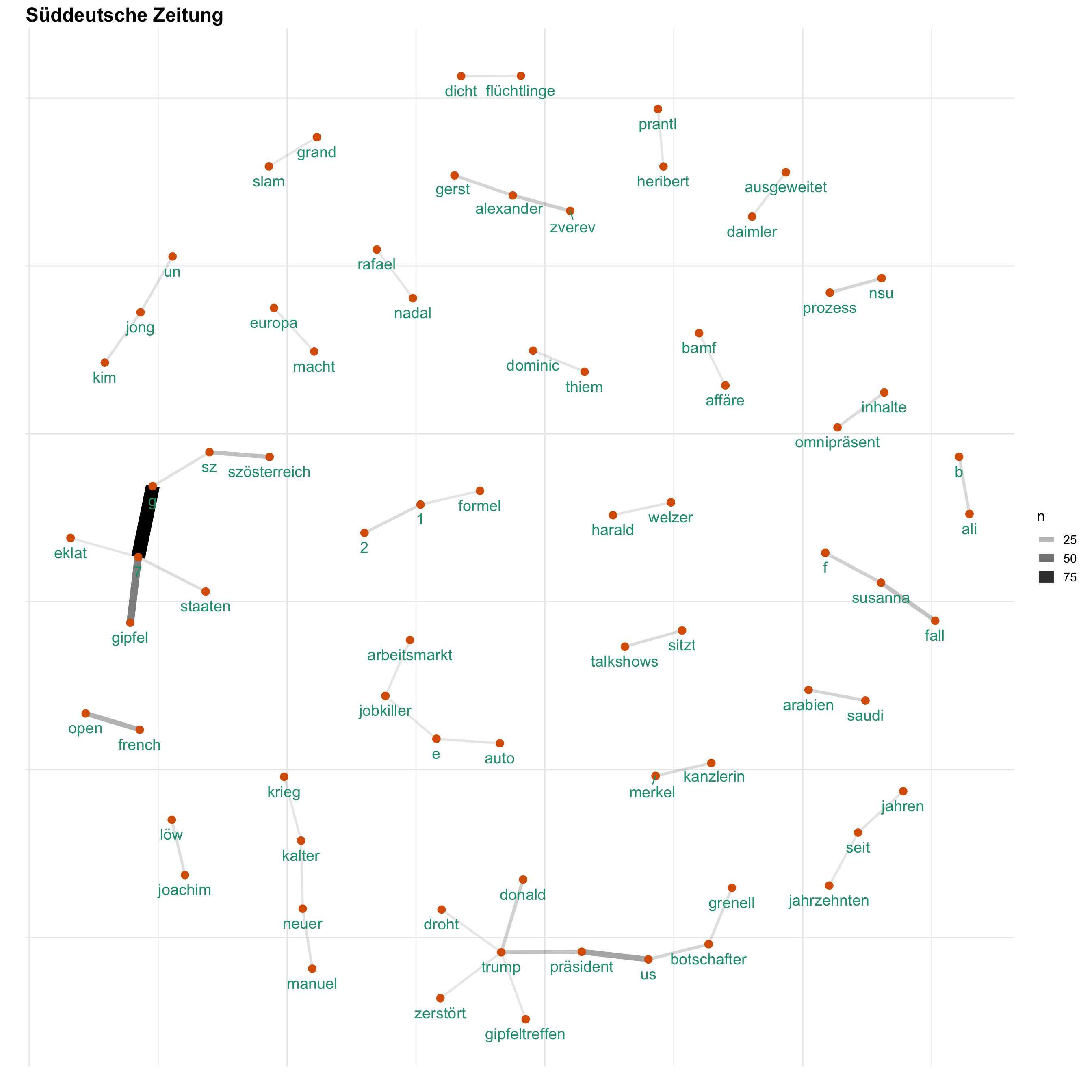
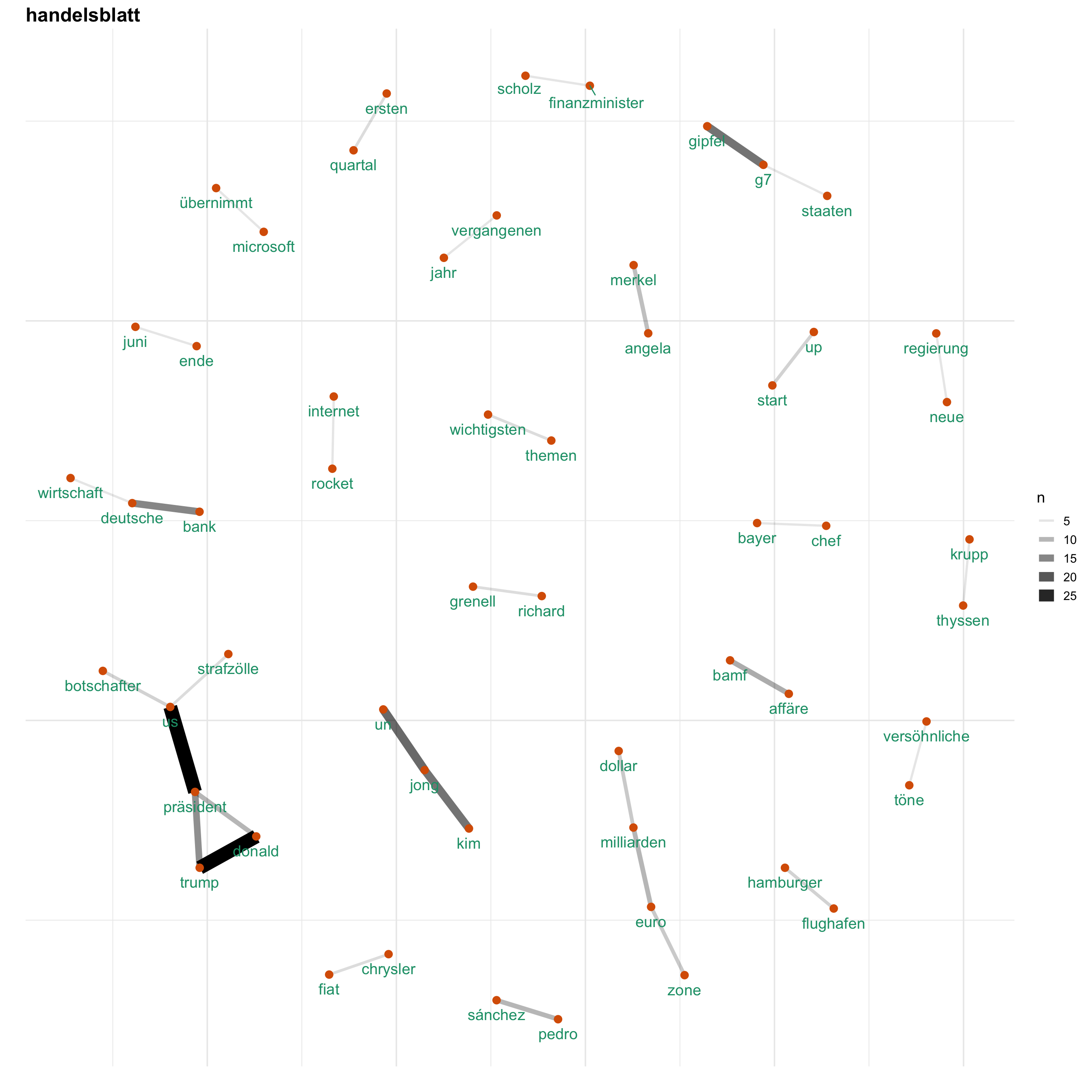
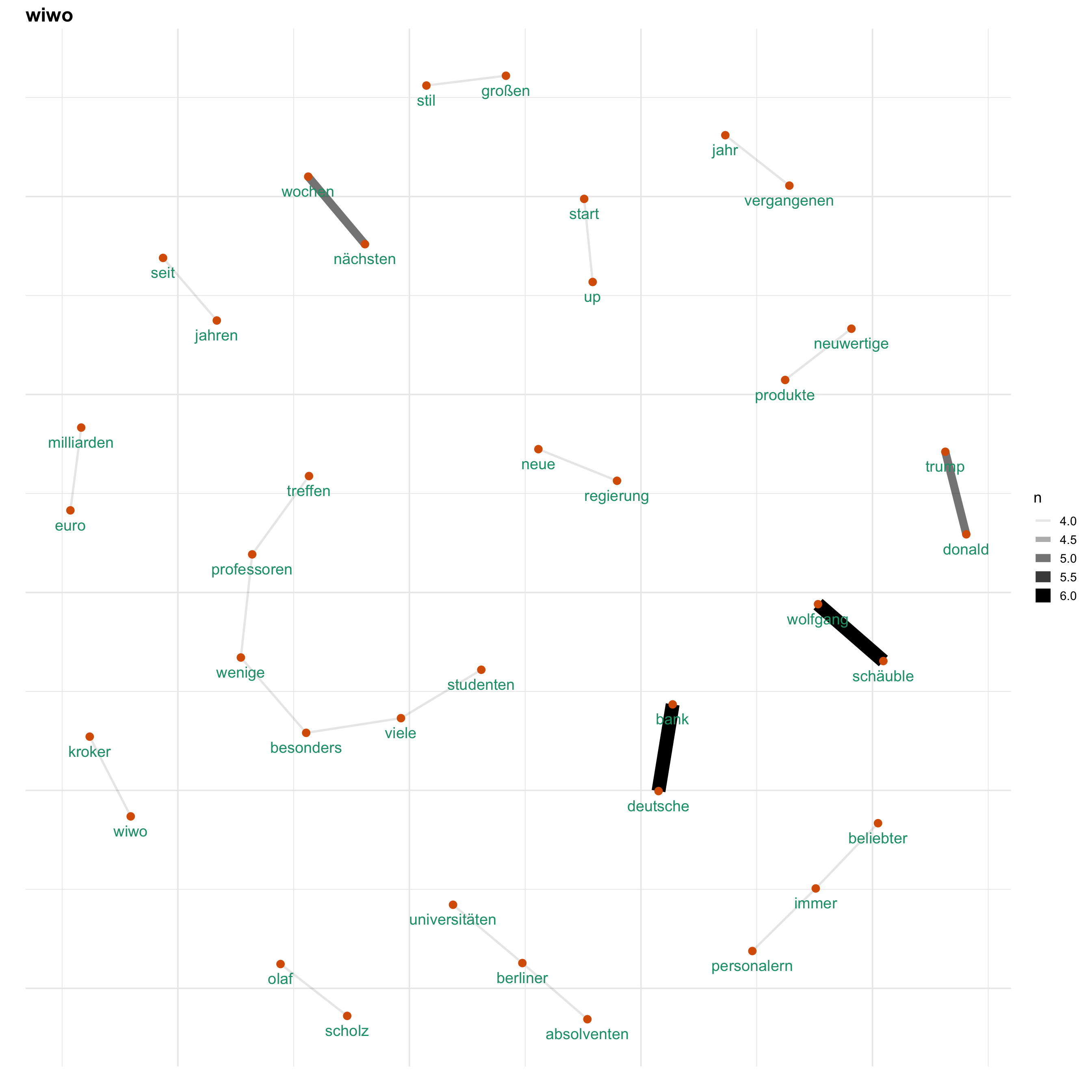
Uns interessiert vorallem, wie Themen bei den verschiedenen Medien besprochen werden. Hierfür gucken wir uns ein Wörter-Netzwerk an, welches anzeigt, welche Wörter wie häufig zusammen verwendet werden. Auf diese Weise wird erkennbar, welche Themen wie miteinander verknüpft sind.
rt_news <- rt_news %>%
mutate(newsName = ifelse(grepl("sz",newsName, ignore.case = T), "Süddeutsche Zeitung", newsName),
newsName = ifelse(grepl("welt",newsName, ignore.case = T), "Die Welt", newsName),
newsName = ifelse(grepl("focus",newsName, ignore.case = T), "FOCUS", newsName),
newsName = ifelse(grepl("faz",newsName, ignore.case = T), "FAZ", newsName)
)
news <- unique(rt_news$newsName)
for (i in news) {
print(word_network(i))
}